




معرفی مدل Claude Opus 4.8؛ عملکرد بهتر از GPT-5.5 و صداقت بیشتر
شرکت آنتروپیک از نسخه جدید هوش مصنوعی خود با نام Claude Opus 4.8 رونمایی کرده است. این مدل که بر پایه نسخه قبلی خود، Opus 4.7، توسعه یافته، در بنچمارکهای مختلف عملکرد بهتری داشته و همکاری موثرتری را با کاربران ارائه میدهد.
ویژگیها و قابلیتهای جدید
Claude Opus 4.8 با چندین ویژگی کاربردی معرفی شده است. کاربران در پلتفرم claude.ai میتوانند میزان تلاش و تفکر مدل را برای انجام یک وظیفه کنترل کنند. پیشتر، گوگل نیز چنین ویژگی را برای جمینای ارائه کرده بود. علاوه بر این، ابزار هوش مصنوعی توسعهدهندگان این شرکت، یعنی Claude Code، به قابلیت جدید «Dynamic Workflows» مجهز شده که به هوش مصنوعی اجازه میدهد صدها زیرعامل (Subagent) را بهصورت موازی برای حل مشکلات بزرگ در سطح کدهای کلان مدیریت و بررسی کند. در این حالت، خود هوش مصنوعی قبل از ارائه گزارش نهایی، خروجی کار را بررسی و ارزیابی میکند.
حالت سریع (Fast mode) برای این مدل ارائه شده است که قادر است با ۲.۵ برابر سرعت بیشتر کار کند و هزینه آن نیز ۳ برابر ارزانتر از مدلهای قبلی است. ویدیو زیر که توسط آنتروپیک منتشر شده، نشان میدهد چگونه ترکیب مدل Claude Opus 4.8 و ابزار Claude Code به برنامهنویسان اجازه میدهد تا وظایف طولانی و پیچیده را به هوش مصنوعی بسپارند.
عملکرد و دقت مدل
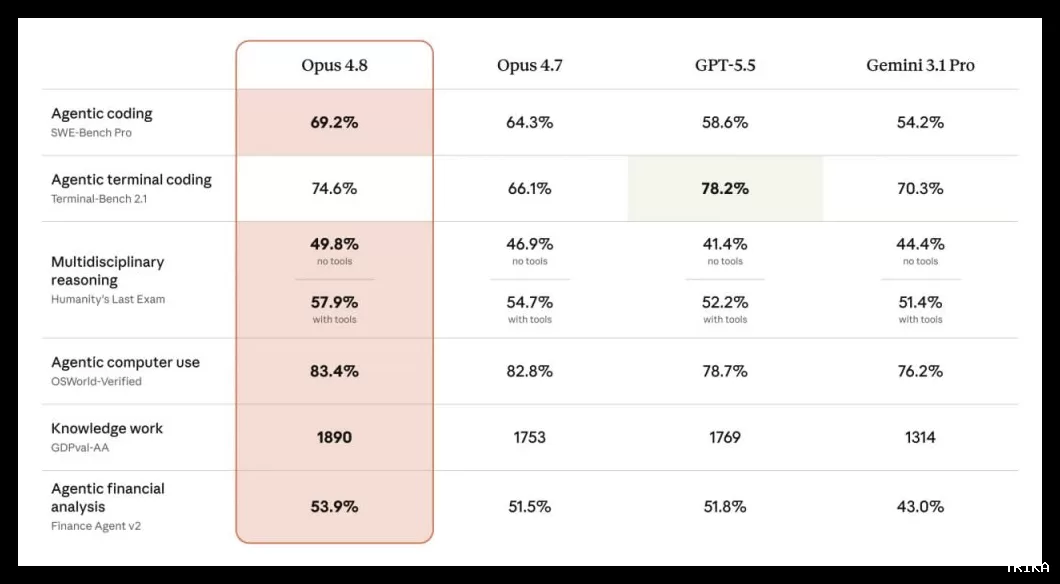
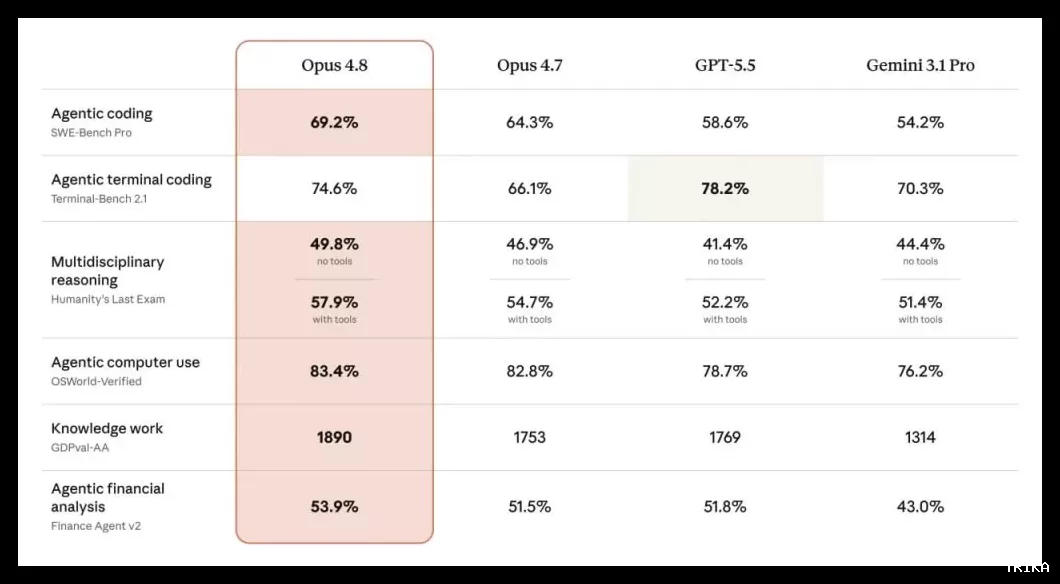
اولین آزمایشکنندگان Claude Opus 4.8 گزارش دادهاند که این مدل در انجام وظایف عاملمحور (Agentic) بسیار قابلاعتمادتر و دقیقتر عمل میکند. طبق دادههای رسمی منتشرشده، Claude Opus 4.8 در بیشتر بنچمارکهای کلیدی هوش مصنوعی نسبت به نسخه قبلی خود و رقبای خود مانند GPT-5.5 و Gemini 3.1 Pro، عملکرد بهتری نشان داده است.
این مدل در آزمون کدنویسی عاملمحور SWE-Bench Pro با کسب امتیاز 69.2 درصد و در بخش استفاده ایجنتی از کامپیوتر (OSWorld-Verified) با امتیاز 83.4 درصد، بالاترین کارایی را در میان تمام مدلها به ثبت رسانده است. در آزمون استدلال چندرشتهای (Humanity's Last Exam)، مدل جدید آنتروپیک چه در حالت بدون ابزار (49.8 درصد) و چه با استفاده از ابزارها (57.9 درصد) پیشتاز رقابت است.
این مدل همچنین در حوزههای تخصصی مورد ارزیابی قرار گرفته و توانسته امتیازات خوبی در کار با دادهها و تحلیلهای مالی بهدست آورد. با این حال، در بنچمارک کدنویسی عاملی در محیط ترمینال (Terminal-Bench 2.1)، GPT-5.5 با امتیاز 78.2 درصد رتبه اول و Opus 4.8 با امتیاز 74.6 درصد در رتبه دوم قرار دارد.
بهبودهای صداقت و خودآگاهی
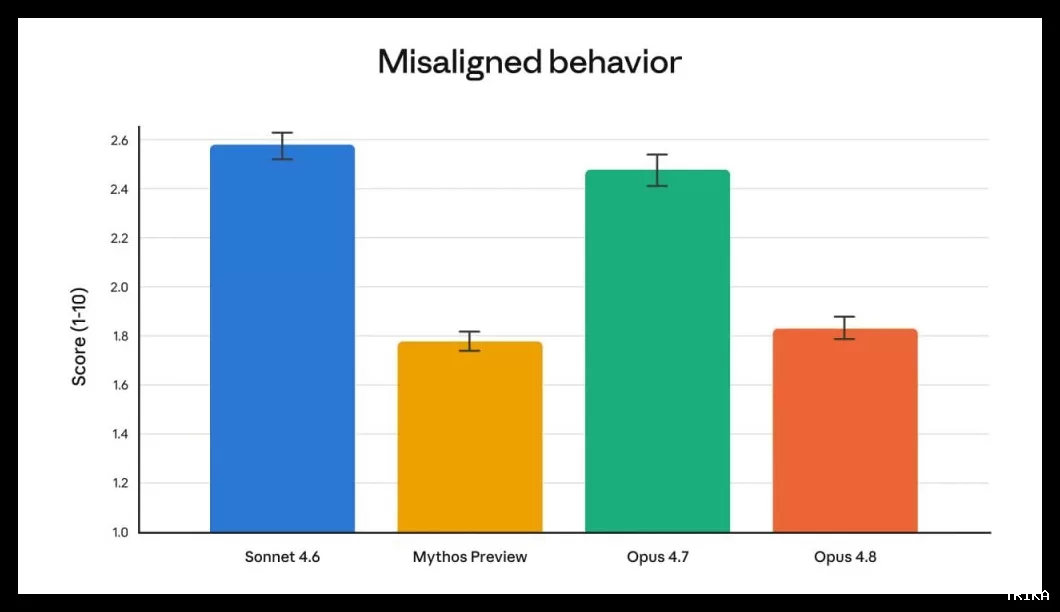
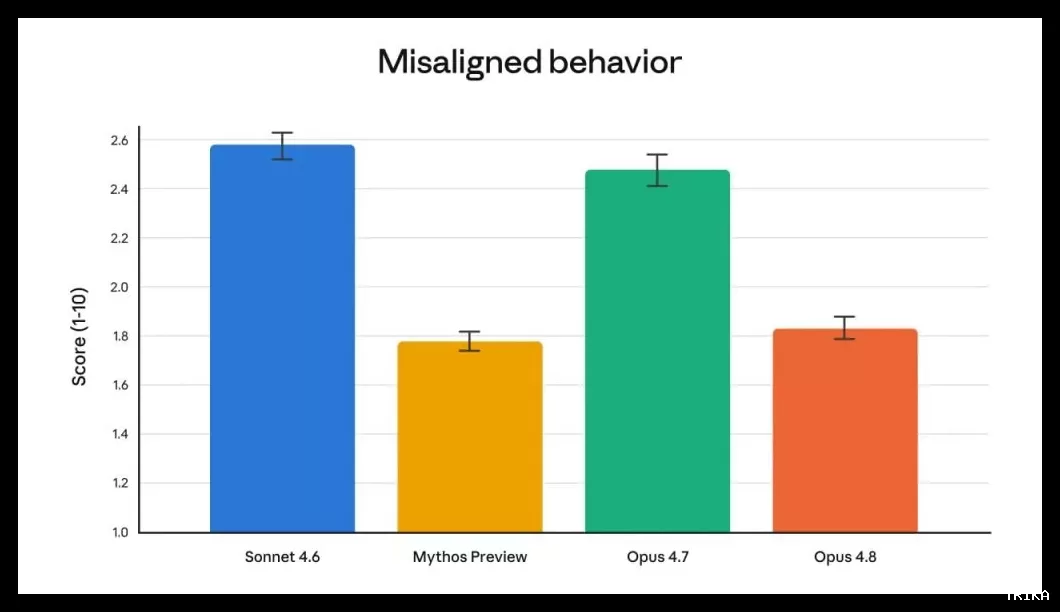
یکی از برجستهترین بهبودهای مدل، افزایش صداقت و خودآگاهی آن است. مدلهای هوش مصنوعی معمولاً تمایل دارند به سرعت نتیجهگیری کنند و ادعاهای بیاساس بکنند. آزمایشهای اولیه نشان میدهند که Opus 4.8 با احتمال بیشتری عدم قطعیتهای خود را اعلام کرده و از ادعاهای بیاساس پرهیز میکند.
ارزیابیها حاکی از آن است که احتمال نادیده گرفتن خطاها در کدهای نوشتهشده توسط این مدل، حدود ۴ برابر کمتر از نسخه قبلی است. رفتارهای نامناسب مدل (مانند فریبکاری) نیز نسبت به نسخه 4.7 کاهش یافته و به سطح ایمنترین مدل این شرکت یعنی Claude Mythos Preview رسیده است.
نمودار ارزیابی رفتارهای نامناسب بهطور پیشفرض روی حالت «پرتلاش» تنظیم شده است که بهترین تعادل را میان کیفیت و تجربه کاربری ایجاد میکند.
قیمتگذاری و برنامههای آینده
آنتروپیک اعلام کرده است که در قالب پروژه Glasswing، مدل پیشرفتهتری به نام Claude Mythos Preview را برای کارهای امنیت سایبری به تعدادی از سازمانها ارائه کرده است. این شرکت قصد دارد پس از اعمال تدابیر امنیتی شدیدتر، مدلهای کلاس Mythos را در هفتههای آینده به صورت عمومی عرضه کند.
هزینه استفاده از Claude Opus 4.8 بدون تغییر باقی مانده است و به ازای هر میلیون توکن ورودی ۵ دلار و هر میلیون توکن خروجی ۲۵ دلار است. همچنین، قیمت حالت سریع ۱۰ دلار برای هر میلیون توکن ورودی و ۵۰ دلار برای هر میلیون توکن خروجی تعیین شده است.