انویدیا تولید انبوه پلتفرم هوش مصنوعی Vera Rubin را آغاز کرد
انویدیا با ورود پلتفرم هوش مصنوعی قدرتمند Vera Rubin به مرحله تولید انبوه، شایعات درباره تأخیر در عرضه این محصول را رد کرد. این پلتفرم که به عنوان «قدرتمندترین پلتفرم هوش مصنوعی ایجنتمحور جهان» شناخته میشود، اکنون آماده استقرار در کارخانههای هوش مصنوعی میباشد.
به گزارش Wccftech، کمتر از دو هفته پیش، انویدیا تولید انبوه پردازندههای مرکزی (CPU) سری Vera را آغاز کرد؛ اقدامی که پیشبینی میشود بازاری ۲۰۰ میلیارد دلاری را پیش روی این شرکت قرار دهد. مدیران انویدیا با اطمینان اعلام کردهاند که با تکیه بر تراشههای Vera، در سال جاری به بزرگترین تأمینکننده CPU در جهان تبدیل خواهند شد. با ورود کامل پلتفرم Vera Rubin NVL72 به فاز تولید، انویدیا اکنون بر تأمین انرژی کارخانههای هوش مصنوعی چند میلیارد دلاری و چند گیگاواتی در سطح جهان تمرکز کرده است.

تولید انبوه پلتفرم هوش مصنوعی Vera Rubin
پلتفرم Rubin انویدیا شامل مجموعهای از ۶ تراشه پیشرفته است که تمامی آنها به آزمایشگاههای انویدیا برای تست نهایی منتقل شدهاند:
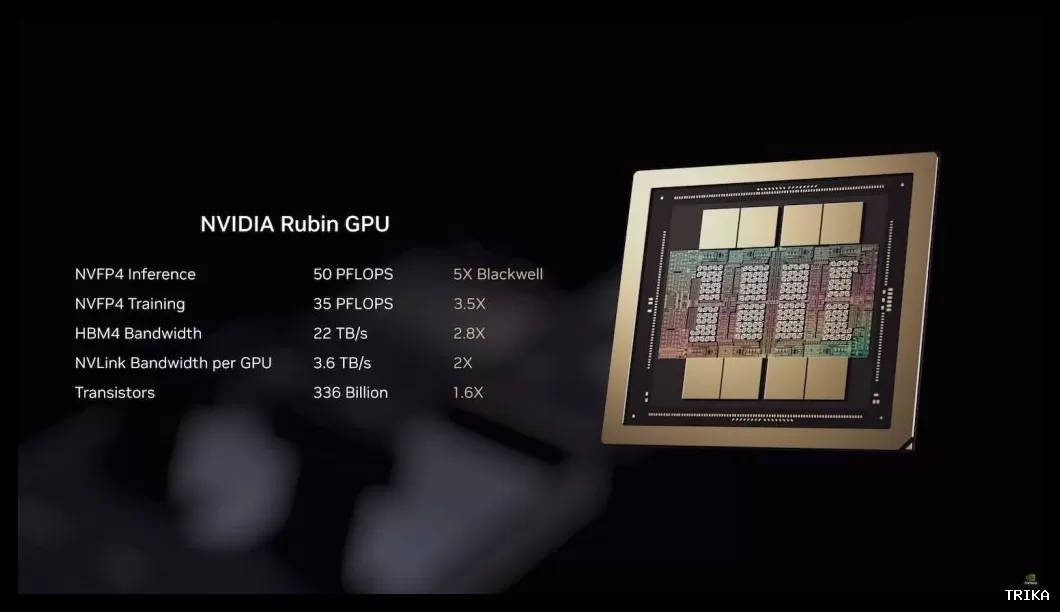
- پردازشگر گرافیکی Rubin GPU: با ۳۳۶ میلیارد ترانزیستور
- پردازنده مرکزی Vera CPU: با ۲۲۷ میلیارد ترانزیستور
- سوئیچ NVLINK 6: برای ارتباط داخلی قطعات
- ماژولهای CX9 و BF4: برای مدیریت شبکه
- ماژول نوری Spectrum-X 102.4T CPO: برای فوتونیک سیلیکونی (انتقال داده با نور)
تراشه Rubin GPU بهطور مخصوص برای پردازشهای سنگین هوش مصنوعی طراحی شده است. این تراشه شامل دو قطعه سیلیکونی Reticle Die با تعداد زیادی هسته محاسباتی و هسته تنسور میباشد. قدرت پردازشی این تراشه به شکل چشمگیری افزایش یافته است:
- ۵۰ پتافلاپس (PFLOPs) عملکرد استنتاج با فرمت NVFP4 (۵ برابر قویتر از نسل قبلی یعنی Blackwell)
- ۳۵ پتافلاپس عملکرد آموزش مدل با فرمت NVFP4 (۳.۵ برابر قویتر از Blackwell)
- پهنای باند حافظه HBM4 تا ۲۲ ترابایت بر ثانیه (۲.۸ برابر سریعتر از Blackwell)
- پهنای باند ارتباطی NVLink تا ۳.۶ ترابایت بر ثانیه به ازای هر CPU (۲ برابر سریعتر از Blackwell)
برای بخش CPU، انویدیا از معماری سفارشی و نسل بعدی آرم با اسم رمز Olympus استفاده کرده است. مشخصات این پردازنده شامل:
- ۸۸ هسته فیزیکی و ۱۷۶ رشته با پشتیبانی از فناوری Spatial Multi-Threading
- ۱.۸ ترابایت بر ثانیه پهنای باند حافظه یکپارچه (NVLink-C2C)
- ۱.۵ ترابایت حافظه سیستم (۳ برابر بیشتر از پردازنده Grace)
- ۱.۲ ترابایت بر ثانیه پهنای باند حافظه با فناوری SOCAMM LPDDR5X
- پشتیبانی از محاسبات محرمانه در سطح رک
ترکیب این ویژگیها موجب گردیده که پردازنده Vera در پردازش دادهها، فشردهسازی و فرایندهای CI/CD عملکردی دو برابر بهتر از پردازنده نسل قبل (Grace) ارائه دهد. ارتباطات درونسیستمی در پلتفرم Rubin بر عهده سوئیچهای نسل ششم NVLink 6 است. این سوئیچها با طراحی مبتنی بر خنککننده مایع، توان محاسباتی درونشبکهای ۱۴.۴ ترافلاپس (با فرمت FP8) را فراهم میکنند.
برای ارتباطات خارجی شبکه نیز از ماژولهای ConnectX-9 و BlueField-4 استفاده میشود. ConnectX-9 SuperNIC پهنای باند ۱.۶ ترابایت بر ثانیه را با پروتکل RDMA ارائه میدهد و برای مقیاسهای بزرگ هوش مصنوعی بهینهسازی شده است. BlueField-4 DPU یک پردازنده ۸۰۰ گیگابیتی است که در واقع یک پردازنده ۶۴ هستهای Grace را با ConnectX-9 ترکیب کرده و ظرفیت شبکه را نسبت به نسل قبل دو برابر میکند.
علاوه بر این، انویدیا از سیستم ارتباطی نوری جدید خود به نام Spectrum-X Ethernet Co-Packaged Optics رونمایی کرده است. این فناوری از فوتونیک سیلیکونی ۲۰۰ گیگابیتی بهره میبرد و سیستم جدید ۵ برابر کارآمدتر، ۱۰ برابر قابلاعتمادتر و دارای ۵ برابر زمان اجرای برنامه بالاتر است.
زمانی که تمام این قطعات پیشرفته در قالب یک رک به نام NVIDIA Vera Rubin NVL72 فراهم میشوند، شاهد جهش خارقالعادهای نسبت به معماری نسل قبل (Blackwell) خواهیم بود:
- ۵ برابر عملکرد بهتر در استنتاج (۳.۶ اگزافلاپس)
- ۳.۵ برابر عملکرد بهتر در آموزش مدل (۲.۵ اگزافلاپس)
- ۲.۵ برابر ظرفیت بیشتر حافظه LPDDR5x (مجموعاً ۵۴ ترابایت)
- ۱.۵ برابر ظرفیت بیشتر حافظه HBM4 (مجموعاً ۲۰.۷ ترابایت)
- ۲.۸ برابر پهنای باند بیشتر حافظه (۱.۶ پتابایت بر ثانیه)
- ۲ برابر پهنای باند ارتباطی Scale-Up بیشتر (۲۶۰ ترابایت بر ثانیه)
برای دیتاسنترهای بزرگ، انویدیا پلتفرم DGX SuperPOD را با ترکیب ۸ رک از مدل NVL72 ارائه میدهد. برای دیتاسنترهای متداولتر نیز مدل DGX Rubin NVL8 پیشبینی شده است. همچنین، پلتفرم ذخیرهسازی Inference Context Memory Storage برای مقیاسهای گیگابایتی استنتاج معرفی شده که به طور کامل با نرمافزارهای انویدیا یکپارچه است. به طور کلی، پلتفرم Vera Rubin به معنای واقعی کلمه هزینهها را کاهش و سرعت را افزایش میدهد.
به گفته انویدیا، استفاده از معماری Rubin در مقایسه با مدل قبلی (Blackwell GB200) باعث کاهش ۱۰ برابری هزینه تولید هر توکن در استنتاج و کاهش ۴ برابری در تعداد GPUهای مورد نیاز برای آموزش مدلهای MoE میشود. در حال حاضر، بزرگترین سازندگان سرور جهان از جمله لنوو، دل، HPE، ایسوس، گیگابایت و فاکسکان در حال تولید انبوه این سیستمها هستند و اولین تراشهها انتظار میرود که اواخر سال جاری میلادی به دست مشتریان برسند.